先日、うっかり 350GB ほどの大規模圧縮ファイル(tar.bz2 形式)を Google Drive にアップロードしてしまいました。目的は NAS を dm-crypt 化する際(下記の記事)のファイル一次退避のため。
しかし困ったことに、アップロードはうまくいったのに対し、ダウンロードがうまくいきません。
ダウンロードエラーとなり、途中で中断されてしまいます。

これではファイルが Google Drive に閉じ込められてしまってローカルに戻すことができません。
今回はその解決策として、Google Drive 上の大規模単一ファイルを数個に分割し、ダウンロードして再結合するまでの手順をメモしていきたいと思います。
試したけどうまくいかなかったこと
Google Drive からファイルをダウンロードする方法は、ブラウザからダウンロードする以外にもいくつかあります。
wget
ダウンロードリンクを使って wget でダウンロードする方法。ただ、こちらは大きいファイルのウイルススキャンが通らず、Google Drive can't scan this file for viruses. といったエラーが出て失敗してしまいます。ブラウザならウイルススキャンを回避できるのですが、wget ではできません。
一方で、今回は試してはいないんですが、こんな回避策もあるようです。
gdown
gdown は Python で Google Drive からファイルをダウンロードするツールです。
また、ファイルをダウンロードするには、Google Drive 側でファイルの共有設定を「リンクを知っている全員に公開」しなければなりません。
Traceback (most recent call last):
File "/home/ytani/.local/lib/python3.12/site-packages/gdown/download.py", line 267, in download
url = get_url_from_gdrive_confirmation(res.text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ytani/.local/lib/python3.12/site-packages/gdown/download.py", line 55, in get_url_from_gdrive_confirmation
raise FileURLRetrievalError(
gdown.exceptions.FileURLRetrievalError: Cannot retrieve the public link of the file. You may need to change the permission to 'Anyone with the link', or have had many accesses. Check FAQ in https://github.com/wkentaro/gdown?tab=readme-ov-file#faq.
更に困ったことに、仮に「リンクを知っている全員に公開」に設定したとしても、なぜか Too many users have viewed or downloaded this file recently. エラーが発生しダウンロードできません。何らかのリソース制限がかかっているのか?ファイルが大きすぎるからなのか?自分の使い方が間違っているのか?原因は判別できていません。
Traceback (most recent call last):
File "/home/ytani/.local/lib/python3.12/site-packages/gdown/download.py", line 267, in download
url = get_url_from_gdrive_confirmation(res.text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ytani/.local/lib/python3.12/site-packages/gdown/download.py", line 53, in get_url_from_gdrive_confirmation
raise FileURLRetrievalError(error)
gdown.exceptions.FileURLRetrievalError: Too many users have viewed or downloaded this file recently. Please try accessing the file again later. If the file you are trying to access is particularly large or is shared with many people, it may take up to 24 hours to be able to view or download the file. If you still can't access a file after 24 hours, contact your domain administrator.
ただ、いずれにせよ gdown は Beautiful soup を使っているようなので、動作はおそらく Web ブラウザから普通にダウンロードするのと変わらないでしょう。
今回の方針:Google Colaboratory でファイル分割しよう
今回は、Google が機械学習用に無料公開している Google Colaboratory を使って、ブラウザでも問題なくダウンロードできるサイズに Google Drive 上のファイルを分割するアプローチで行きたいと思います。
Google Colaboratory の特徴
Google Colaboratory は、Google のサーバ上で Jupyter Notebook を実行できるプラットフォームです。
基本的には機械学習環境の提供を目的としていて、リソース制限はあるものの、ある程度無料で GPU や TPU を利用できます。自分も以前、機械学習や推論でお世話になったことがあります。
機械学習用ではあるんですが、基本は Jupyter Notebook です。Python がメインではありますが、通常の Linux コマンドもサーバ上で実行できますし、今回は使いませんがネットワークからファイルをダウンロードしたりアップロードすることもできます(しかも Google の爆速ネットワークで!)。
更に良いことに、Google Colaboratory からは Google Drive のマウントが可能です。つまり、自分の Google Drive 上のファイルに対して Linux コマンドや Python で何らかの操作や書き込みをしたり、コピーしたり、移動したりすることができます。これを使えばローカル環境を介さずとも、Google Drive 上で大規模ファイルを分割できます。
手順
Google Colaboratory でノートブックを作成
Google Colab に行き、新しいノートブックを作成します。Google Drive 上に作成しておくと便利です。
ランタイム(実行環境)の接続を待機します。画面右上が「待機中」となっていればまだ接続中です。
「RAM」「ディスク」と表示されたら接続完了です。
接続が完了したら、左側のメニューからファイルアイコンを選択します。
そしたら、Google Drive に接続するために、目のアイコンの左隣のフォルダアイコン(に小さい Google Drive のアイコンが描かれているもの)を選択します。
Google Drive へ接続するか確認されますので、「Google ドライブに接続」を選択します。
フォルダ一覧に「drive」が出てきたら完了です。これで Google Colaboratory から Google Drive にアクセスできるようになりました。
ファイル分割用スクリプトの用意
コマンドを自分で逐一実行しても良いですが、今回は簡単に分割できるスクリプトを用意しました。
あるファイルを均等に分割し、dd コマンドで書き出すスクリプトです。
#!/bin/bash
# 環境変数:
# INPUT: 元ファイルの絶対パス
# OUTDIR: 出力フォルダ
# CHUNK_GB: 分割サイズ(GB)
# PART_INDEX: 何回目の分割か(0から開始)
# PREFIX: 出力ファイル名の接頭辞
if [ -z "$INPUT" ] || [ -z "$OUTDIR" ] || [ -z "$CHUNK_GB" ] || [ -z "$PART_INDEX" ] || [ -z "$PREFIX" ]; then
echo "必要な環境変数が設定されていません。"
exit 1
fi
# 出力先
mkdir -p "$OUTDIR"
# skip サイズ
SKIP_GB=$((CHUNK_GB * PART_INDEX))
# 出力ファイル名
OUTFILE="${OUTDIR}/${PREFIX}_${PART_INDEX}.bin"
echo "=== 分割実行 ==="
echo "INPUT : $INPUT"
echo "OUTFILE : $OUTFILE"
echo "CHUNK SIZE : ${CHUNK_GB}GB"
echo "PART INDEX : ${PART_INDEX}"
echo "SKIP : ${SKIP_GB}GB"
echo "================="
# dd 実行
dd if="$INPUT" of="$OUTFILE" bs=1G skip="$SKIP_GB" count="$CHUNK_GB" status=progress
echo "=== 出力完了: $OUTFILE ==="
今回はこのスクリプトファイルを Google Drive の適当な場所にアップロードしておき、Google Colaboratory から実行することにします。
ノートブック上で実行する
ここまでできたら、ノートブック上でスクリプトを実行します。
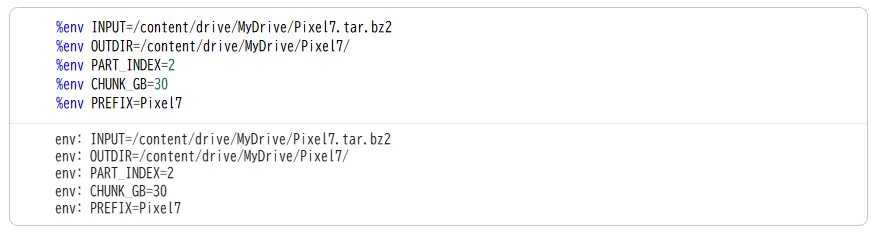
…とその前に、入力ファイル INPUT や出力先ディレクトリ OUTDIR、分割回数 PART_INDEX、分割サイズ CHUNK_GB、出力ファイルの接頭辞 PREFIX といった必要な環境変数を設定しておきます。
ちなみに Google Colaboratory 上で環境変数を設定するには、通常の export コマンドではなく %env を用います。これは Jupyter Notebook の仕様によるもので、Jupyter Notebook ではデフォルトで Python コードを実行する仕様になっているので、コマンドを実行するには % ないしは ! を先頭につけて実行する必要があります。% から始まるものはは %cd や %env といった IPython から提供されるもの(マジックコマンド)、! は通常のコマンド実行(システムコマンド)です。
%env INPUT=/content/drive/MyDrive/Pixel7.tar.bz2
%env OUTDIR=/content/drive/MyDrive/Pixel7/
%env PART_INDEX=0
%env CHUNK_GB=30
%env PREFIX=Pixel7
今回は 30GB ずつとしました。PART_INDEX は 0 のとき 0~30GB 目が、1 のとき 30GB ~ 60GB、2 のとき 60 GB~90GB、…と分割されてファイル出力されます。
再生ボタンをクリックして実行すると env: なんとかかんとか が出力されます。これで下準備は完了です。
いよいよ分割を実行していきます。!bash で先程のスクリプトのファイルパスを指定して実行してください。
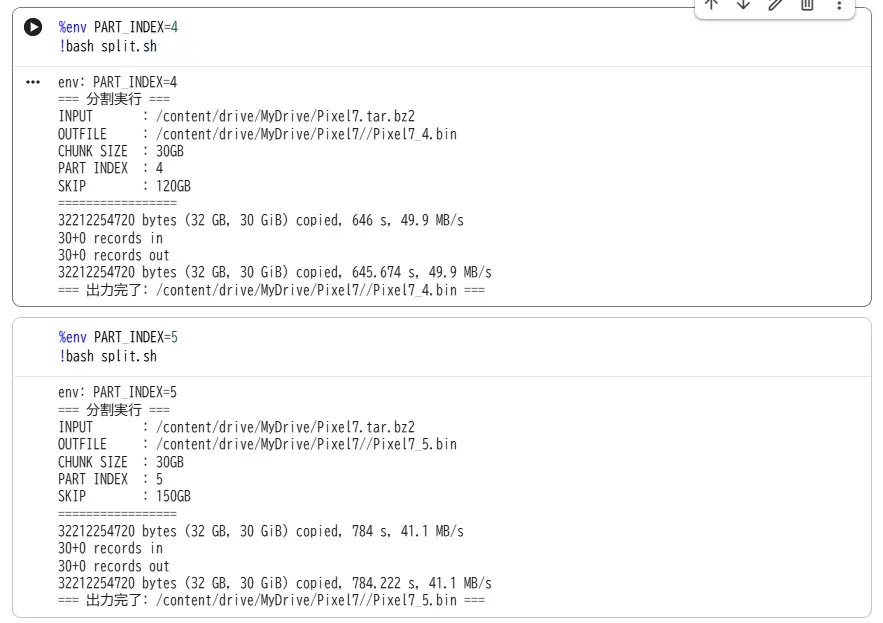
!bash split.sh
こんな表示になったら成功です(画像は3回目)。
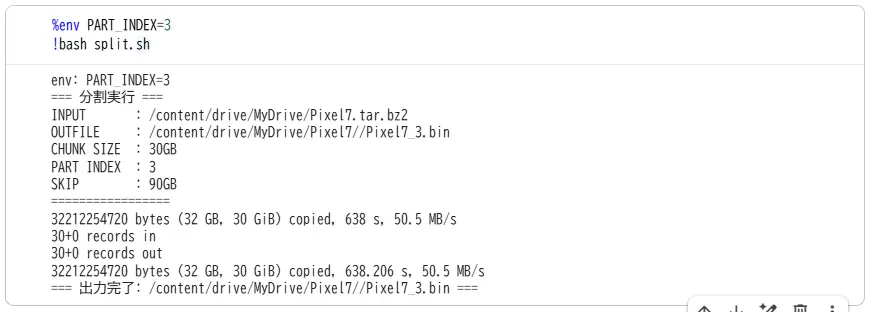
これを PART_INDEX=1、PART_INDEX=2、…と増やして各分割パートを出力していきます。
実行時の注意
Google Colaboratory にはリソース制限があります。これはファイルの書き出しも同様です。

初期状態では 70GB 弱が利用可能となっていて、これが 0 になるとコマンドが強制停止されてしまいます。
おそらくこれは一時的なストレージで、書き出し中に使われるストレージです。最終的には(出力先に Google Drive を指定した場合は)Google Drive に書き出されるのですが、一旦は分割したファイルが一時ストレージに書き出される模様です。
それで、どういう計算になっているのかは不明ですが、だいたい 35GB くらい書き出すと残り 0 GB になってしまうんですよね。もしかしたら read アクセスと write アクセスを別々にカウントしているのかもしれません。
一度ファイルを書き出すと、Google Drive に実際に反映されるまでに数分程度かかります。Google Drive に反映されたら、このストレージ容量がリセットされ、再び 70GB 弱が使用可能になります。
以上の点から、分割サイズは 30GB 程度にとどめておいて、一つずつ実行し、一回分が完了したら数分空けてまた実行…とする必要があります。
ダウンロード&ローカルで再結合
分割が完了したら、各分割パートをダウンロードして手元の環境で再結合します。
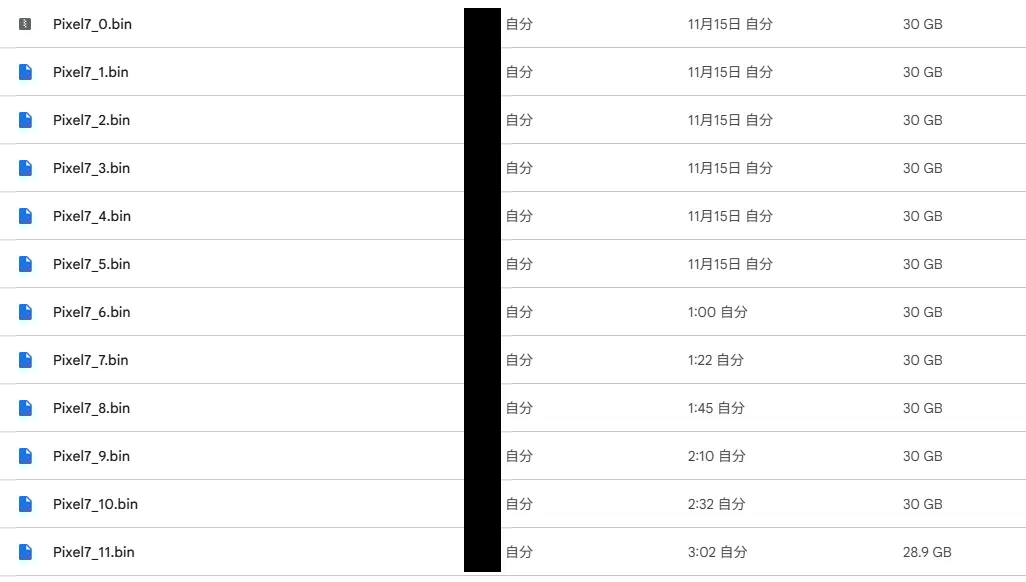
今回は12分割になりました。まずはブラウザでダウンロードしていきます。30GB 程度のファイルであれば問題なくダウンロードできました。
$ ls
Pixel7_0.bin Pixel7_10.bin Pixel7_2.bin Pixel7_4.bin Pixel7_6.bin Pixel7_8.bin
Pixel7_1.bin Pixel7_11.bin Pixel7_3.bin Pixel7_5.bin Pixel7_7.bin Pixel7_9.bin
これを cat コマンドとリダイレクトを使って結合していきます。
ちなみに、下記のように実行すると、結合のファイルサイズに対してもう1つ分の空き容量が必要になります。なぜなら、分割パートファイルが削除されないまま結合後のファイルが生成されるからですね。
$ cat Pixel7_0.bin Pixel7_1.bin Pixel7_2.bin ... Pixel7_11.bin >> Pixel7.tar.bz2
空き容量を節約したい場合は、パートファイルごとに追記モードで順次結合していきましょう。結合が済んだファイルはその都度削除します。こうすると、分割サイズ分だけ空き容量があれば済みます。
mv Pixel7_0.bin Pixel7.tar.bz2
cat Pixel7_1.bin >> Pixel7.tar.bz2
rm Pixel7_1.bin
cat Pixel7_2.bin >> Pixel7.tar.bz2
rm Pixel7_2.bin
...
cat Pixel7_11.bin >> Pixel7.tar.bz2
rm Pixel7_11.bin
最終的に、元のファイルサイズの単一ファイルになりました。
-rw-rw-r-- 1 ytani ytani 359G 11月 16 09:33 Pixel7.tar.bz2
圧縮ファイルの展開についても、特にエラーなく実施できています。
実行後の確認
本当は sha256 などでハッシュ値を計算してファイルの欠損がないかチェックしたかったんですが、Google Colaboratory 側のリソース制限により、350GB 以上あるファイルからハッシュ値を計算することができませんでした。read アクセスだけでもリソース制限に引っかかってしまうようですね。
というわけで、file stat の比較だけで勘弁してください。
Google Drive 上の file stat
# stat drive/MyDrive/Pixel7.tar.bz2
File: drive/MyDrive/Pixel7.tar.bz2
Size: 385366776402 Blocks: 752669486 IO Block: 65536 regular file
Device: 2fh/47d Inode: 67 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2025-09-29 13:02:52.000000000 +0000
Modify: 2025-11-16 03:57:27.000000000 +0000
Change: 2025-11-16 03:57:27.000000000 +0000
Birth: -
再結合後の file stat
$ stat /mnt/usbhdd2/Pixel7.tar.bz2
File: /mnt/usbhdd2/Pixel7.tar.bz2
Size: 385366776402 Blocks: 752669568 IO Block: 4096 通常ファイル
Device: 254,4 Inode: 12 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ ytani) Gid: ( 1000/ ytani)
Access: 2025-11-16 14:00:19.255477954 +0900
Modify: 2025-11-16 09:33:39.905020079 +0900
Change: 2025-11-16 12:59:15.498660897 +0900
Birth: 2025-11-16 11:01:55.816857862 +0900
IO Block などに違いが生じていますが、これはファイルシステムの差異によるものです。ファイルサイズは一致しているので、大丈夫でしょう…多分!
おわりに
Google Colaboratory は Goole Drive 上のファイルを操作するのに非常に便利です。Google は各種サービスが連携できて自由に活用できるところがいいですね。