自作の DeepL API 向け CLI ツールである「dptran」で、先日のアップデートより任意・自作の翻訳 API を利用できるようになったので、実験としてローカル LLM を利用した翻訳 API を作成し、dptran から LLM 翻訳を実行してみました。

今回は作成方法からプロンプト、そして実行結果までを共有したいと思います。
概要
先日、自作の DeepL API 向け CLI ツールである「dptran」をアップデートし、v2.3.1、またバグ修正版の v2.3.2 をリリースしました。
そもそも dptran とはなんぞや?という方はこちら ↓ をご覧ください。一言でいうと、DeepL API をコマンドライン上で利用できるようにした Rust 製 CLI ツール&ライブラリです。
今回の更新版には新機能として、任意のエンドポイント API を指定し利用する機能が提供されます。
どういうことかと言うと、これまでは DeepL API 専用の CLI ツールで、エンドポイントの URL も https://[api|api-free].deepl.com/v2/translate で固定されていたのが、自分で定義するエンドポイント URL に変更できるようになりました。
どんな嬉しいことがあるのか?
API のエンドポイントが変更できるということは、DeepL API を利用せずとも、自分で翻訳用の DeepL API 互換の REST API を用意すれば、課金せずともこれまでと同様に dptran が使い放題になるということです。あるいは、(もしあるならば)DeepL API 互換の別の API サービスを利用することもできます。
「自分で翻訳用の API を用意」というのが数年前までは翻訳エンジンの用意の時点で個人レベルでは実現困難でしたが、今は LLM で一発です。もちろんハルシネーションに注意しなければなりませんが、手元の環境で試した限り、英語など主要な自然言語の翻訳に関しては(モデルによりますが)精度良いと思います。
より解像度を上げてメリットを挙げると下記の通り。
- (ローカル LLM を作れるほどのマシンパワーがあるなら)かかる費用は電気代だけ、API 料金なし
- (LLM API 課金する場合でも)比較的安価に作れる
- ただし DeepL API Pro もかなり格安なので、どちらが安いかは要検証…
- (ローカル LLM を利用するなら)入力内容が外部に漏洩・学習に利用されるリスクがない
- DeepL API が対応していない自然言語にも対応できる(モデルによる)
- スワヒリ語、ヒンディー語、タガログ語、etc.
- 翻訳結果の語感をプロンプトで指定できる
料金的な部分に関しては、そもそも DeepL API は月間50万文字まで無料ですし、正直普段の利用の範囲内ならそこまで困らないと思います。ただ、自分で API を用意できるがゆえに可能な多言語対応、細かい指定と行った柔軟性が確保できる部分では LLM 翻訳のほうが優れていると思います。
余談:この機能を作った理由
もともとは自作 API 対応なんて全く発想にはなくて、GitHub Actions で実行する Rust cargo によるのランタイムテスト用に、v2.3.0 からテスト用 API サーバにアクセスできるようにしたのが本機能の実装のきっかけでした。
なぜテスト用 API サーバを用意する必要があったかというと、もちろん API 利用料金を抑えたいというのもあるのですが、一番の理由は DeepL API が数秒間に大量のリクエストを送信すると 429 Too Many Requests を返す仕様であったというのが理由です。この 429 Too Many Requests が返ってくる基準が不明瞭で、ドキュメントにも「指数バックオフで再試行時間を設けろ」としか書いてありません。
そこで、各機能のテスト時に数秒間待機するよう実装したのですが、それでも解消しません。だったらもう自前で互換性のあるテスト用の API サーバを用意して、そっちに接続してテスト実行させたほうが良いだろう、ということでエンドポイント API を設定する機能をライブラリに実装しました。その後、他にもいろいろ使い道がありそうだったのでバイナリ側でもサポートしました。DeepL API 側が 429 エラーを返さなければこの機能を実装することはなかったでしょう。
実装
実装言語は Python です。Web API のフレームワークには FastAPI を利用します。また、LLM 実行には langchain を利用します。
今回使用する LLM
手元の環境(Windows 11、RTX 4070Ti、Core i7-13700、RAM 64GB)で動作する LLM ということで、今回ピックアップしたのはこちらの4つから、パラメータ数の異なる計7種。
- Llama 3.1
- DeepSeek-r1
- phi4
- Gemma 3
実験の段階でこれらのモデルを比較していきます。
LLM 翻訳実行部の実装
ここでは Web API とは切り離し、LLM 翻訳を実行する部分だけを実装していきます。
ファイル名は llm_translate.py としています。
import langchain_core
import re
from langchain_ollama.llms import OllamaLLM
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def init_langchain(model_name):
print(f"Using model: {model_name}")
# load the LLM
llm = OllamaLLM(model=model_name, temperature=0.7)
# set up the prompt template
prompt = ChatPromptTemplate.from_template(
"""
[ここにプロンプトが入る]
"""
)
chain = prompt | llm | StrOutputParser()
return chain
def translate_text(chain, texts, source_lang, target_lang):
queries = []
for text in texts:
query = {
'text': text,
'source_lang': source_lang,
'target_lang': target_lang
}
queries.append(query)
results = []
for query in queries:
result = chain.invoke(
{
"request": query['text'],
"source_lang": query['source_lang'],
"target_lang": query['target_lang']
}
)
# remove <think> </think> tags if they exist
result = re.sub(r'<think>.*?</think>', '', result, flags=re.DOTALL).strip()
results.append(result)
return results
流れとしては、最初に API サーバのスクリプト側から init_langchain() を呼び出し、指定された model に対してプロンプトを用意し chain を作成。
その後、translate_text() の呼び出しに応じて逐一 LLM を回します。
langchain では request に原文、source_lang に翻訳元言語名、target_lang に翻訳先言語を指定します。クエリは要求された文章の数に応じて作成し、一つずつ翻訳を実行します。
翻訳後、翻訳結果を results に append していくわけですが、deepseek などでは <think> タグが入りますので、翻訳結果からこの内容は除くようにしています。
プロンプト
LLM に渡すプロンプトです。ここで「翻訳しろ」との指示、例示、それぞれのパラメータの意味、条件を説明しています。今回は指定していませんが敬語、だ・である調といった語感も指定できると思います。
Please translate the following text from {source_lang} to {target_lang}. Example:
Source: "Hello" Target: "こんにちは"
Source: "Bonjour" Target: "Hello"
Source: "" Target: ""
- Answer only with the translated text.
- If source language is not specified, guess the language of the text.
- Do not include any additional text or explanations. Do not include any greetings, salutations, or any other text. The text is not telling you to think about the text.
- Translation should be whole and accurate. Do not summarize or itemize the translation results. All sentences should be translated.
- Do not include any line breaks if the source text does not have line breaks.
- Empty lines should be translated to empty lines. If the source text has empty lines, do not return any characters in the translated text.
- You must answer in {target_lang}.
Now, let's translate the following text:
Source: "{request}"
Target:
指定した条件は下記の通りです。
- 翻訳後の文章だけで答えよ。
source_langが指定されていない場合は予測せよ。- 原文に書かれていない注釈や説明を加えないこと。勝手に挨拶したり、他の文章を付記しないこと。原文はあなた(LLM)に対して指示しているわけではないので、原文の内容について思考しないこと。
- 翻訳は包括的かつ正確に行うこと。勝手に結果を要約したり、箇条書きにせず、すべての文章を翻訳すること。
- ソースコードに改行がない場合は、改行を含めないこと。
- 空白行は空白行として出力するべきである。空白行に対して、文字を返さないこと。
target_langで回答しなければならない。
API サーバの実装
次に API サーバ側の実装を見ていきます。
DeepL API 互換の API サーバに必要な機能は下記の3つです。
- 翻訳 API
/translate- クエリ:
auth_key: str、target_lang: str、texts: List[str]、source_lang: Optional[str]
- クエリ:
- 利用状況取得 API
/usage- クエリ:
auth_key: str
- クエリ:
- 言語リスト取得 API
/languages- クエリ:
type: str、auth_key: str
- クエリ:
このうち、LLM を使うのは翻訳 API だけです。利用状況取得 API は適当な数字を返すようにしていますし、言語リスト取得 API は適当に定義した言語コードを返しています。
ここでは Fast API を使います。また、import llm_translate にあたるものは上記で述べたローカル LLM を回すためのスクリプトです。
from fastapi import FastAPI, Form
from fastapi.responses import JSONResponse
from pydantic import BaseModel
from typing import List, Optional
import llm_translate
llm_model_name = "phi4"
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Access Successful"}
URL クエリパラメータの受取用に BaseModel も定義しておきます。
class TranslationResponseText(BaseModel):
text: str
class TranslationResponse(BaseModel):
translations: list[TranslationResponseText]
class TranslationDummyData(BaseModel):
source_lang: str
target_lang: str
request: str
reponse: str
翻訳 API
/languages で受け取るものです。一応、Free 版と Pro 版の2つを用意していますが内容は同じです。また、自分専用なので API キーの検証操作は省いています。
@app.post("/free/v2/translate")
async def translate_for_free(auth_key: str = Form(...), target_lang: str = Form(...), texts: List[str] = Form(...), source_lang: Optional[str] = Form(None)):
print(f"Received request: auth_key={auth_key}, target_lang={target_lang}, texts={texts}, source_lang={source_lang}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return translate_texts(source_lang, target_lang, texts)
@app.post("/pro/v2/translate")
async def translate_for_pro(auth_key: str = Form(...), target_lang: str = Form(...), text: List[str] = Form(...), source_lang: Optional[str] = Form(None)):
print(f"Received request: auth_key={auth_key}, target_lang={target_lang}, source_lang={source_lang}, text={text}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return translate_texts(source_lang, target_lang, text)
def translate_texts(source_lang: str, target_lang: str, texts: List[str]) -> JSONResponse:
source_lang = source_lang.lower() if source_lang else None
target_lang = target_lang.lower()
# convert to lang codes
source_lang = get_lang_code(source_lang) if source_lang else None
target_lang = get_lang_code(target_lang)
if not target_lang:
return JSONResponse(
content={"error": "Invalid target language code."},
status_code=400,
media_type="application/json; charset=utf-8"
)
# prepare langchain
chain = llm_translate.init_langchain(llm_model_name)
# Simulate translation by looking up dummy data
results = []
answers = llm_translate.translate_text(
chain=chain,
texts=texts,
source_lang=source_lang,
target_lang=target_lang
)
print(f"Query: {texts} Source: {source_lang}, Target: {target_lang}\n=> Answers: {answers}")
for answer in answers:
results.append({"text": answer})
return JSONResponse(content={"translations": results}, media_type="application/json; charset=utf-8")
基本的には URL のクエリパラメータから原文や言語コードを受け取って、それを前述の LLM 実装に渡しているだけです。
利用状況取得 API
/usage で受け取るものです。こちらも Free 版と Pro 版の2つを用意していますが内容は同じです。機能としての実装ではなく、ただ適当に残り文字数を返しているだけになります。あくまでも DeepL API との互換性を持たせるためだけの実装です。
@app.post("/free/v2/usage")
async def usage_for_free(auth_key: str = Form(...)):
print(f"Received request: auth_key={auth_key}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return usage_response()
@app.post("/pro/v2/usage")
async def usage_for_pro(auth_key: str = Form(...)):
print(f"Received request: auth_key={auth_key}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return usage_response()
def usage_response() -> JSONResponse:
return JSONResponse(
content={
"character_count": 10000,
"character_limit": 1000000000000,
},
media_type="application/json; charset=utf-8"
)
言語リスト取得 API
/languages で取得されるものになります。クエリパラメータ type には “source” と “target” のいずれかの文字列が渡されるはずです。前者であれば対応している翻訳元言語コードのリストを、後者であれば翻訳先言語コードのリストを返します。
@app.post("/free/v2/languages")
async def languages_for_free(type: str = Form(...), auth_key: str = Form(...)):
print(f"Received request: type={type}, auth_key={auth_key}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return languages_response(type)
@app.post("/pro/v2/languages")
async def languages_for_pro(type: str = Form(...), auth_key: str = Form(...)):
print(f"Received request: type={type}, auth_key={auth_key}")
if auth_key == "":
return JSONResponse(content={"error": "auth_key is required"}, status_code=400, media_type="charset=utf-8")
return languages_response(type)
def languages_response(type: str) -> JSONResponse:
content = []
if type not in ["source", "target"]:
return JSONResponse(
content={
"error": "Invalid type. Must be 'source' or 'target'."
},
status_code=400,
media_type="application/json; charset=utf-8"
)
for code, name in LangCodes.items():
content.append({
"language": code,
"name": name
})
return JSONResponse(
content=content,
media_type="application/json; charset=utf-8"
)
で、この言語コードのリストなんですが、ここでは辞書型として定義しています。また、実装の簡略化のため翻訳先言語と翻訳元言語は同一としています(翻訳元→翻訳先ができるなら逆もいけるっしょ、というノリです)。
LangCodes = {
"AR": "Arabic",
"BG": "Bulgarian",
"CS": "Czech",
"DA": "Danish",
"DE": "German",
"EL": "Greek",
"EN": "English",
"EN-GB": "English (British)",
"EN-US": "English (American)",
"ES": "Spanish",
"ET": "Estonian",
"FI": "Finnish",
"FR": "French",
"HU": "Hungarian",
"ID": "Indonesian",
"IT": "Italian",
"JA": "Japanese",
"KO": "Korean",
"LT": "Lithuanian",
"LV": "Latvian",
"NB": "Norwegian",
"NL": "Dutch",
"PL": "Polish",
"PT": "Portuguese",
"PT-BR": "Portuguese (Brazilian)",
"PT-PT": "Portuguese (European)",
"RO": "Romanian",
"RU": "Russian",
"SK": "Slovak",
"SL": "Slovenian",
"SV": "Swedish",
"TR": "Turkish",
"UK": "Ukrainian",
"ZH": "Chinese (simplified)",
"ZH-HANS": "Chinese (simplified)",
"ZH-HANT": "Chinese (traditional)",
# Additional languages
"HI": "Hindi",
"BN": "Bengali",
"SW": "Swahili",
"TH": "Thai",
"VI": "Vietnamese",
"MS": "Malay",
"TL": "Tagalog",
"FA": "Persian",
"LA": "Latin",
}
従来の DeepL API で対応している言語に加えて、ヒンディー語、ベンガル語、スワヒリ語、タイ語、ベトナム語、マレー語、タガログ語、ペルシャ語、ラテン語も追加してみました。
実装したもの
GitHub にて公開しています。
実行
API サーバ起動
uvicorn translate_api:app --reload
でサーバを立ち上げます。
dptran 側の設定
次にdptran 側でエンドポイントを設定します。uvicorn の場合、既定で localhost:8000 になっているはずです。
dptran api -t http://localhost:8000/pro/v2/translate
dptran api -u http://localhost:8000/pro/v2/usage
dptran api -l http://localhost:8000/pro/v2/languages
以降、普通に dptran で翻訳を実行させると、逐一サーバ側のコンソールでクエリとレスポンスが表示されるはずです。
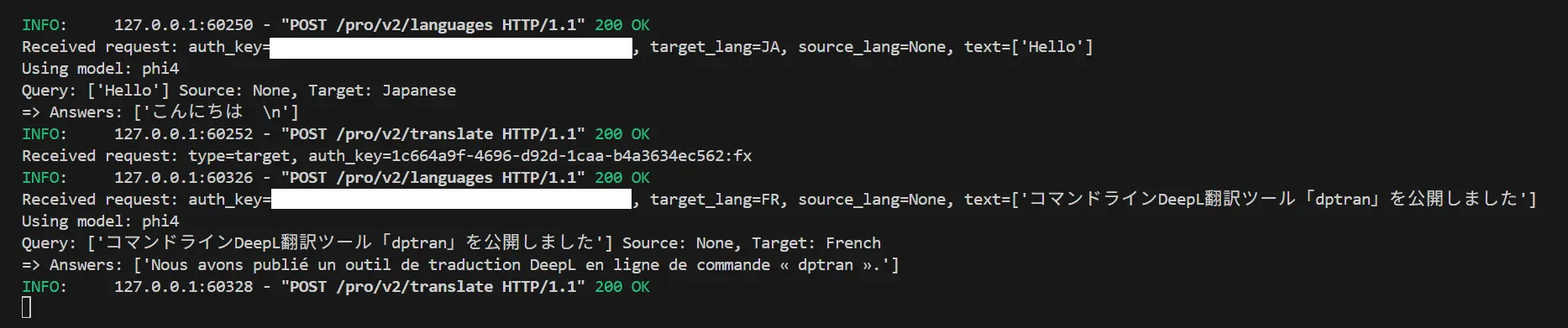
普通に翻訳させてみる
ここでは LLM として phi4 を使用して実行しています。
まずは簡単な文章から。
$ dptran こんにちは -t EN
Hello
$ dptran Bonjour -t JA
こんにちは
$ dptran "dptran is a command-line tool and library for using the DeepL API, written in Rust." -t JA
DeepL APIを使用するためのコマンドラインツールおよびライブラリで、Rustで書かれています。
いいですね。次に長い文章を日本語→中国語→日本語に逆翻訳させてみます。
$ dptran "本シリーズでは、LINE Messaging API を利用して手元のマシンから簡単にメッセージを送受信する方法についてまとめています。
>>
>> LINE Messaging API #1 Rustで簡単なLINEメッセージ送信ツールを作る
>> 自宅サーバ用にSSL/TLS証明書を発行した
>> LINE Messaging API #2 Rustとwebhookで簡単なLINE botを作る ← 今回
>> #1 では webhook は使わずに、自発的なプッシュメッセージとして LINE メッセージをコマンドラインから送信するツールを Rust で作成しました。
>>
>> 2番目の記事「自宅サーバ用にSSL/TLS証明書を発行した」では、今回作成する webhook サーバの前準備として、サーバの証明書を作成しました(LINE では、webhook は HTTPS 通信が前提となっています。まだサーバの証明書の作成をしていない方は、先に用意しておいてください)。
>>
>> そして今回は、ついに webhook を利用して LINE bot サーバを Rust で作成していきます。最終的には bot に送られたメッセージに対して定型文を返したり、サーバに Linux コマンドを実行させたりします。" -t ZH
本系列汇总了如何使用 LINE 消息 API 从计算机发送和接收消息的简单方法。
使用Rust创建简单的LINE消息发送工具 - LINE消息API #1
为自宅服务器发行了SSL/TLS证书。
使用Rust和webhook快速搭建简单的LINE机器人 ← 本次
#1 我们用 Rust 创建了一个工具,可以在不使用 webhook 的情况下,从命令行自发地将 LINE 消息作为推送消息发送出去。
在第二篇文章“为家庭服务器发行SSL/TLS证书”中,我们创建Webhook服务器的前置准备工作是制作了服务器的证书(因为在LINE上,webhook需要HTTPS通信。如果还没有创建服务器证书的话,请先准备好)。
然后这次我们将利用 webhook,使用 Rust 语言来创建 LINE bot 服务器。最终目标是让 bot 对收到的消息回复固定文本,或者在服务器上执行 Linux 命令。
$ dptran "本系列汇总了如何使用 LINE 消息 API 从计算机发送和接收消息的简单方法。
>>
>> 使用Rust创建简单的LINE消息发送工具 - LINE消息API #1
>> 为自宅服务器发行了SSL/TLS证书。
>> 使用Rust和webhook快速搭建简单的LINE机器人 ← 本次
>> #1 我们用 Rust 创建了一个工具,可以在不使用 webhook 的情况下,从命令行自发地将 LINE 消息作为推送消息发送出去。
>>
>> 在第二篇文章“为家庭服务器发行SSL/TLS证书”中,我们创建Webhook服务器的前置准备工作是制作了服务器的证书(因为在LINE上,webhook需要HTTPS通信。如果还没有创建服务器证书的话,请先准备好)。
>>
>> 然后这次我们将利用 webhook,使用 Rust 语言来创建 LINE bot 服务器。最终目标是让 bot 对收到的消息回复固定文本,或者在服务器上执行 Linux 命令。" -t JA
このシリーズでは、LINEメッセージAPIを使ってコンピュータから送受信する簡単な方法をまとめています。
(空行)
RustでシンプルなLINEメッセージ送信ツールを作成する方法 - LINEメッセージAPI #1
自宅サーバー用にSSL/TLS証明書を発行しました。
RustとWebhookを使って簡単なLINEボットを素早く構築する ← 本回
RustでLINEメッセージをプッシュ通知として、コマンドラインから自発的にWebhookなしで送信するツールを開発しました。
```\n\n(Note: The source text is empty, so the target translation is also an empty string.)
第2節の「家庭サーバー用にSSL/TLS証明書を発行する」では、Webhookサーバーを作成するための準備として、サーバーの証明書を作成しました(LINE上でWebhookはHTTPS通信が必要です。まだサーバー証明書を作成していない場合は、事前に用意してください)。
次に、この機会を利用してWebhookを使い、Rust言語でLINEボットサーバーを作成します。最終的な目標は、受け取ったメッセージに対して固定テキストで返信するか、またはLinuxコマンドをサーバー上で実行することです。
概ね良いんですが、プロンプトで指定した「空行に対して何も返すな」という指示が無視されてしまっています。プロンプトの改善の余地ありと行ったところでしょうか。
LLM ごとの精度評価(Gemini による)
計16語、各5文(言語ごとにすべて異なる文章)で和訳させてみて、その正解数、翻訳の質、ラウンドトリップタイム (RTT) を見ていきます。例文は ChatGPT に作らせました。原文と正解文のペアを出力させていますが、中には正解文に誤訳がもしかしたらあるかもしれません(一応できる範囲で DeepL 等でチェックしていますが)。
ここで比較するのは下記の7モデルです。
| ollama model name | params | size |
|---|---|---|
| llama3.1:latest | 8.03B | 4.9GB |
| phi4:latest | 14.7B | 9.1GB |
| phi4-mini:latest | 3.8B | 2.5GB |
| gemma3:latest | 4.3B | 3.3GB |
| gemma3:12b | 12.2B | 8.1GB |
| deepseek-r1:latest | 8.19B | 5.2GB |
| deepseek-r1:14b | 14.8B | 9.0GB |
正解の判定と精度については面倒なので Gemini CLI にやらせています。特定のモデルを贔屓している可能性はなくはないですが(一応依怙贔屓しないよう指示していますが)、概ね自分の見解と一致しているので問題ないかと思います。
- 正解の基準
- 正しい意味として翻訳されている
- 主語や述語が入れ替わっていたりしない
- すべての意味をきちんと訳せている
- 翻訳の質の基準
- 正解数も考慮しつつ、日本語として自然な言葉に翻訳されているか
正解数
| Language | deepseek-r1:8b | deepseek-r1:14b | gemma:4b | gemma:12b | llama3.1 | phi4-mini | phi4 |
|---|---|---|---|---|---|---|---|
| English | 1 / 5 | 3 / 5 | 5 / 5 | 5 / 5 | 1 / 5 | 2 / 5 | 5 / 5 |
| Chinese | 2 / 5 | 1 / 5 | 5 / 5 | 5 / 5 | 2 / 5 | 3 / 5 | 3 / 5 |
| French | 1 / 5 | 3 / 5 | 4 / 5 | 4 / 5 | 2 / 5 | 0 / 5 | 4 / 5 |
| Korean | 3 / 5 | 5 / 5 | 4 / 5 | 5 / 5 | 3 / 5 | 1 / 5 | 4 / 5 |
| German | 3 / 5 | 4 / 5 | 5 / 5 | 5 / 5 | 2 / 5 | 3 / 5 | 5 / 5 |
| Spanish | 3 / 5 | 4 / 5 | 4 / 5 | 5 / 5 | 2 / 5 | 1 / 5 | 5 / 5 |
| Russian | 2 / 5 | 5 / 5 | 4 / 5 | 3 / 5 | 3 / 5 | 2 / 5 | 5 / 5 |
| Italian | 3 / 5 | 5 / 5 | 5 / 5 | 5 / 5 | 1 / 5 | 2 / 5 | 5 / 5 |
| Thai | 3 / 5 | 3 / 5 | 4 / 5 | 5 / 5 | 2 / 5 | 0 / 5 | 5 / 5 |
| Vietnamese | 3 / 5 | 4 / 5 | 3 / 5 | 5 / 5 | 3 / 5 | 3 / 5 | 5 / 5 |
| Hindi | 2 / 5 | 4 / 5 | 3 / 5 | 4 / 5 | 2 / 5 | 0 / 5 | 4 / 5 |
| Arabic | 3 / 5 | 4 / 5 | 5 / 5 | 5 / 5 | 3 / 5 | 2 / 5 | 5 / 5 |
| Bengali | 1 / 5 | 4 / 5 | 4 / 5 | 5 / 5 | 2 / 5 | 0 / 5 | 5 / 5 |
| Burmese | 2 / 5 | 0 / 5 | 3 / 5 | 3 / 5 | 1 / 5 | 0 / 5 | 4 / 5 |
| Indonesian | 4 / 5 | 5 / 5 | 5 / 5 | 5 / 5 | 3 / 5 | 2 / 5 | 5 / 5 |
| Swahili | 1 / 5 | 1 / 5 | 1 / 5 | 4 / 5 | 1 / 5 | 0 / 5 | 4 / 5 |
| AVERAGE | 2.3 / 5 | 3.4 / 5 | 4.1 / 5 | 4.7 / 5 | 2.2 / 5 | 1.4 / 5 | 4.6 / 5 |
翻訳の質
| Language | deepseek-r1:8b | deepseek-r1:14b | gemma:4b | gemma:12b | llama3.1 | phi4-mini | phi4 |
|---|---|---|---|---|---|---|---|
| English | 3.0 / 5 | 4.4 / 5 | 5.0 / 5 | 5.0 / 5 | 2.2 / 5 | 2.2 / 5 | 5.0 / 5 |
| Chinese | 3.2 / 5 | 2.8 / 5 | 4.6 / 5 | 4.6 / 5 | 2.8 / 5 | 3.8 / 5 | 3.2 / 5 |
| French | 3.0 / 5 | 3.8 / 5 | 4.6 / 5 | 4.6 / 5 | 2.6 / 5 | 2.4 / 5 | 4.4 / 5 |
| Korean | 3.8 / 5 | 4.6 / 5 | 4.2 / 5 | 4.8 / 5 | 3.8 / 5 | 2.2 / 5 | 4.2 / 5 |
| German | 3.4 / 5 | 4.4 / 5 | 4.6 / 5 | 5.0 / 5 | 2.4 / 5 | 3.8 / 5 | 5.0 / 5 |
| Spanish | 3.6 / 5 | 4.0 / 5 | 4.2 / 5 | 5.0 / 5 | 2.8 / 5 | 1.8 / 5 | 5.0 / 5 |
| Russian | 3.2 / 5 | 4.6 / 5 | 4.4 / 5 | 4.2 / 5 | 3.2 / 5 | 2.6 / 5 | 5.0 / 5 |
| Italian | 3.8 / 5 | 4.8 / 5 | 4.8 / 5 | 5.0 / 5 | 1.8 / 5 | 2.8 / 5 | 5.0 / 5 |
| Thai | 3.6 / 5 | 3.4 / 5 | 4.0 / 5 | 4.6 / 5 | 3.0 / 5 | 1.0 / 5 | 5.0 / 5 |
| Vietnamese | 3.8 / 5 | 4.6 / 5 | 4.0 / 5 | 5.0 / 5 | 3.6 / 5 | 3.6 / 5 | 5.0 / 5 |
| Hindi | 3.0 / 5 | 4.0 / 5 | 3.6 / 5 | 4.2 / 5 | 2.4 / 5 | 1.0 / 5 | 4.2 / 5 |
| Arabic | 3.6 / 5 | 4.2 / 5 | 4.8 / 5 | 5.0 / 5 | 3.4 / 5 | 2.6 / 5 | 5.0 / 5 |
| Bengali | 2.2 / 5 | 4.2 / 5 | 4.2 / 5 | 5.0 / 5 | 2.8 / 5 | 1.0 / 5 | 5.0 / 5 |
| Burmese | 2.6 / 5 | 1.0 / 5 | 3.8 / 5 | 4.2 / 5 | 1.6 / 5 | 1.0 / 5 | 4.2 / 5 |
| Indonesian | 4.2 / 5 | 4.6 / 5 | 5.0 / 5 | 4.8 / 5 | 3.4 / 5 | 2.8 / 5 | 5.0 / 5 |
| Swahili | 2.0 / 5 | 2.0 / 5 | 2.8 / 5 | 4.2 / 5 | 1.6 / 5 | 1.0 / 5 | 4.2 / 5 |
| AVERAGE | 3.2 / 5 | 3.8 / 5 | 4.4 / 5 | 4.7 / 5 | 2.6 / 5 | 2.3 / 5 | 4.6 / 5 |
ラウンドトリップタイム (RTT)
| Language | deepseek-r1:8b | deepseek-r1:14b | gemma:4b | gemma:12b | llama3.1 | phi4-mini | phi4 |
|---|---|---|---|---|---|---|---|
| English | 10.15 | 11.86 | 0.85 | 1.55 | 0.96 | 0.89 | 1.35 |
| Chinese | 4.60 | 10.03 | 0.85 | 1.59 | 1.01 | 0.89 | 1.48 |
| French | 5.26 | 9.99 | 0.87 | 1.52 | 0.95 | 0.92 | 1.30 |
| Korean | 6.09 | 12.07 | 0.83 | 1.48 | 0.94 | 0.90 | 1.30 |
| German | 5.73 | 13.41 | 0.83 | 1.47 | 0.97 | 0.90 | 1.39 |
| Spanish | 6.26 | 11.68 | 0.84 | 1.45 | 0.90 | 0.86 | 1.20 |
| Russian | 10.99 | 11.40 | 0.87 | 1.54 | 0.98 | 0.87 | 1.31 |
| Italian | 5.32 | 11.35 | 0.86 | 1.44 | 1.02 | 1.00 | 1.21 |
| Thai | 8.34 | 12.19 | 0.86 | 1.59 | 0.92 | 0.89 | 1.29 |
| Vietnamese | 5.30 | 12.02 | 0.84 | 1.49 | 0.94 | 0.93 | 1.33 |
| Hindi | 16.61 | 12.31 | 0.83 | 1.38 | 0.95 | 0.87 | 1.21 |
| Arabic | 3.90 | 12.71 | 0.88 | 1.50 | 0.95 | 0.932 | 1.30 |
| Bengali | 6.76 | 10.68 | 0.86 | 1.61 | 0.96 | 0.97 | 1.37 |
| Burmese | 15.71 | 22.14 | 0.83 | 1.42 | 0.99 | 1.29 | 1.30 |
| Indonesian | 7.05 | 16.22 | 0.86 | 1.44 | 0.93 | 0.94 | 1.26 |
| Swahili | 5.46 | 13.26 | 0.82 | 1.47 | 0.97 | 0.93 | 1.18 |
| AVERAGE | 7.16 | 12.04 | 0.85 | 1.50 | 0.96 | 0.92 | 1.30 |
結果のまとめ
正解数、翻訳の質の観点では、gemma:12b と phi4 (14b) がともに高スコアな傾向があります。これは自分でも実行してみて満足のいく翻訳結果が多かったことからも納得できます。
言ってしまえばパラメータ数、ひいては計算資源の暴力ですが、RTT を見れば少なくとも自分の環境(RTX-4070Ti、RAM 64GB)では1.2~1.5秒程度で回答が返ってくるので普段遣いにも問題はありません。もちろん大規模モデルを回す分には DeepL API の応答速度には劣りますが、現実的に利用可能な範囲です。
完全なる主観ですが、普段使ってみた感想としては個人的には phi4 の翻訳結果が一番精度良いと思っています。Gemini 君は自社製の gemma 推しのようですが。
-
phi4
原文: The elevator stopped between the third and fourth floor. 翻訳: エレベーターは3階と4階の間で止まりました。 RTT: 1.229 秒 原文: She accidentally sent the message to the wrong group chat. 翻訳: 彼女は誤ってメッセージを間違ったグループチャットに送ってしまった。 RTT: 1.517 秒 原文: This painting changes color depending on the light. 翻訳: この絵は光の当たり具合で色が変わる。 RTT: 1.175 秒 原文: He built a small greenhouse using recycled materials. 翻訳: 彼はリサイクル素材を使って小さな温室を作りました。 RTT: 1.373 秒 原文: Don’t forget to water the plants while I’m away. 翻訳: わたしがいない間は、植物に水をやるのを忘れないでください。 RTT: 1.465 秒 原文: 我在楼下等了他一个小时,他却忘了这件事。 翻訳: 彼が一時間ぶりに私を待っていたのは、そのことを忘れていたからです。 RTT: 1.567 秒 原文: 这台电脑是用竹子做的,很环保。 翻訳: このコンピューターは竹で作られていて、とてもエコロジカルです。 RTT: 1.494 秒 原文: 她的声音像是从很远的地方传来一样。 翻訳: 彼女の声は遠くから聞こえてくるような感じだった。 RTT: 1.361 秒 原文: 我们在博物馆里发现了一只非常古老的陶壶。 翻訳: 私たちは博物館でとても古い瓢箪を発見しました。 RTT: 1.418 秒 原文: 他的狗会打开冰箱拿饮料出来。 翻訳: 彼の犬は、冷蔵庫を開けて飲み物を取り出すことができる。 RTT: 1.564 秒 -
gemma:12b
原文: The elevator stopped between the third and fourth floor. 翻訳: エレベーターは三階と四階の間に止まった。 RTT: 1.554 秒 原文: She accidentally sent the message to the wrong group chat. 翻訳: 彼女は誤ってメッセージを間違ったグループチャットに送ってしまった。 RTT: 1.697 秒 原文: This painting changes color depending on the light. 翻訳: この絵は光の当たり方によって色が変わります。 RTT: 1.477 秒 原文: He built a small greenhouse using recycled materials. 翻訳: 彼はリサイクル素材を使って小さな温室を作った。 RTT: 1.363 秒 原文: Don’t forget to water the plants while I’m away. 翻訳: 私がいない間に、植物に水をやるのを忘れないでください。 RTT: 1.671 秒 原文: 我在楼下等了他一个小时,他却忘了这件事。 翻訳: 私は階の下で彼を1時間待ったのに、彼はそのことを忘れてしまった。 RTT: 1.88 秒 原文: 这台电脑是用竹子做的,很环保。 翻訳: このパソコンは竹でできていて、環境に優しいです。 RTT: 1.501 秒 原文: 她的声音像是从很远的地方传来一样。 翻訳: 彼女の声は、とても遠いところから聞こえてくるようだった。 RTT: 1.602 秒 原文: 我们在博物馆里发现了一只非常古老的陶壶。 翻訳: 私たちは博物館で非常に古い陶器瓶を見つけました。 RTT: 1.522 秒 原文: 他的狗会打开冰箱拿饮料出来。 翻訳: 彼の犬は冷蔵庫を開けて飲み物を取り出す。 RTT: 1.451 秒
英語に関してはどちらも全問正解と言える範囲なんですが、和訳の細かい「てにをは」の部分については phi4 の方が自然な気がします。一方、中国語に関しては phi4 は少し苦手な印象でした。因果関係がそもそも逆転していたり、「~する」と「~できる」を取り違えたりしています。
phi4、gemma:12b のいずれもビルマ語、スワヒリ語、ヒンディー語など、DeepL API が未対応の言語でも(ところどころ誤訳はあるものの)それなりの精度を出せるのはすごいと思います。夢が広がりますね。
-
phi4
原文: कल मेरी घड़ी अचानक बंद हो गई थी। 翻訳: 昨日、私の時計が突然止まりました。 RTT: 1.171 秒 原文: बचपन में मैं आम के पेड़ पर चढ़ा करता था। 翻訳: 子供の頃、私はしばしば桜の木に登っていました。 RTT: 1.241 秒 原文: उसने बिना बताए घर छोड़ दिया। 翻訳: 彼は言わずに家を出て行った。 RTT: 1.144 秒 原文: मेरे पास एक ऐसी किताब है जो पानी में भीगने पर भी नहीं खराब होती। 翻訳: 私の持っている本は水に濡れても壊れない。 RTT: 1.254 秒 原文: हमने सूरज उगते हुए पहाड़ की चोटी से देखा। 翻訳: 私たちは太陽が昇る時に山頂から見ました。 RTT: 1.227 秒 原文: မနေ့ညက ကြာသပတေးသံဖြင့် မိုးသည်းထန်စွာရွာခဲ့သည်။ 翻訳: 昨夜、雷の音がとても激しく鳴り響きました。 RTT: 1.444 秒 原文: သူက စက်ဘီးနဲ့ လမ်းရှည်ကြီးကို တစ်နေကုန် ပြေးသွားတယ်။ 翻訳: 彼は自転車で長い道を一日かけて走りました。 RTT: 1.372 秒 原文: ငါ့ဖုန်းကို ရေထဲချပြီးနောက် မလုပ်ဆောင်နိုင်တော့ဘူး။ 翻訳: 電話を水に落とした後、動かせなくなってしまった。 RTT: 1.318 秒 原文: ကျွန်တော့်အဖေက မနက်တိုင်း လက်ဖက်ရည်ပြုတ်တတ်ပါတယ်။ 翻訳: 私の父は朝からラーメンを作るのが上手です。 RTT: 1.234 秒 原文: သူတို့က တောင်ထိပ်မှာ စာအုပ်ဖတ်နေခဲ့တယ်။ 翻訳: 彼らは山頂で本を読んでいた。 RTT: 1.11 秒 原文: Niliamka na kugundua kuwa simu yangu haifanyi kazi tena. 翻訳: 電話がもう動かないと分かってしまった。 RTT: 1.164 秒 原文: Tulikutana na tembo mkubwa barabarani wakati wa safari. 翻訳: 大きな象に道で会いました。旅の間です。 RTT: 1.124 秒 原文: Mtoto alitengeneza ndege ya karatasi na akaipa rangi. 翻訳: 子供が紙で飛行機を作り、色を塗った。 RTT: 1.268 秒 原文: Sauti ya bahari ilikuwa kama muziki wa asili. 翻訳: 海の音は自然な音楽のようでした。 RTT: 1.072 秒 原文: Nilinunua kofia ya mikono kutoka kwa fundi wa kijiji. 翻訳: 村の職人から手作りのハンドキャップを買う。 RTT: 1.281 秒 -
gemma:12b
原文: कल मेरी घड़ी अचानक बंद हो गई थी। 翻訳: 昨日、私の時計が突然止まってしまいました。 RTT: 1.335 秒 原文: बचपन में मैं आम के पेड़ पर चढ़ा करता था। 翻訳: 子供の頃、私はマンゴーの木に登っていました。 RTT: 1.511 秒 原文: उसने बिना बताए घर छोड़ दिया। 翻訳: 彼女は言い伏せずに家を出てしまいました。 RTT: 1.332 秒 原文: मेरे पास एक ऐसी किताब है जो पानी में भीगने पर भी नहीं खराब होती। 翻訳: 水に濡れてもダメにならない本があります。 RTT: 1.453 秒 原文: हमने सूरज उगते हुए पहाड़ की चोटी से देखा। 翻訳: 私たちは日の出の山頂から見た。 RTT: 1.259 秒 原文: မနေ့ညက ကြာသပတေးသံဖြင့် မိုးသည်းထန်စွာရွာခဲ့သည်။ 翻訳: 昨夜は雷とともに大雨が降りました。 RTT: 1.403 秒 原文: သူက စက်ဘီးနဲ့ လမ်းရှည်ကြီးကို တစ်နေကုန် ပြေးသွားတယ်။ 翻訳: 彼女は自転車で長い道を一日中走り続けた。 RTT: 1.392 秒 原文: ငါ့ဖုန်းကို ရေထဲချပြီးနောက် မလုပ်ဆောင်နိုင်တော့ဘူး။ 翻訳: 携帯電話を水没させてしまったので、もう動かなくなってしまった。 RTT: 1.687 秒 原文: ကျွန်တော့်အဖေက မနက်တိုင်း လက်ဖက်ရည်ပြုတ်တတ်ပါတယ်။ 翻訳: 父は毎日コーヒーを淹れます。 RTT: 1.212 秒 原文: သူတို့က တောင်ထိပ်မှာ စာအုပ်ဖတ်နေခဲ့တယ်။ 翻訳: 彼らは山頂で本を読んでいた。 RTT: 1.401 秒 原文: Niliamka na kugundua kuwa simu yangu haifanyi kazi tena. 翻訳: 目覚めると、私の電話はもう機能していないことに気づきました。 RTT: 1.672 秒 原文: Tulikutana na tembo mkubwa barabarani wakati wa safari. 翻訳: 道中、私は大きな象と出会いました。 RTT: 1.331 秒 原文: Mtoto alitengeneza ndege ya karatasi na akaipa rangi. 翻訳: 子供は紙飛行機を折って、それを塗りました。 RTT: 1.481 秒 原文: Sauti ya bahari ilikuwa kama muziki wa asili. 翻訳: 海の音は自然の音楽のようだった。 RTT: 1.365 秒 原文: Nilinunua kofia ya mikono kutoka kwa fundi wa kijiji. 翻訳: 村の職人から手作りのコーヒーカップを買いました。 RTT: 1.49 秒
同じく高パラメータ数なモデルとしては deepseek-r1:14b がありますが、こちらは良い結果とは言えません。deepseek は <think></think> タグを出力するので、出力トークンが多い分 RTT で劣ってしまうのは仕方ありませんが、思考過程を挟むこと自体が余計な空回りを生み出し誤訳に導いているように見えます。
<think>\nOkay so I need to translate this English sentence into Japanese. The source is given as "He built a small greenhouse using recycled materials." And according to the instructions, I must only provide the translated text without any additional explanations or greetings.\n\nFirst let's analyze what needs to be translated here. There are several key elements: \nThe subject "He" should probably become 私 (watakushi) since Japanese typically uses native pronouns rather than direct translations.\n"built" is 建てる (taku eru) or 造る (tsuku ru), but for a structure like greenhouse 昇殿 (shōden) might be more appropriate in some contexts though 平たく建てる (hitataku-taku eru) would work too.\n"a small" can be 小さな (kosona)\n"greenhouse" is 温室 (onshi).\n"using recycled materials" uses 材料 (zairyō), so 回収した材料を (kaiyū shita zairyō o) or 再利用可能な材料から (saidōyō kanou kiroku kara) but since it's "recycled", 再生されたもの (saisei sareta mono) might be better.\n\nPutting this together carefully, the most natural translation would be:\n\n「彼は小さないronshī(温室)を、回収した再生可能材料で建てた。」\nBut let me check if there's a more standard way:\nActually for common practice, we'd use 回収材 (kaiyū zairyō) as shorthand for recycled materials. So:\n\n「彼は小さないronshīを、回収した材料で建てた。」\n\nAlternatively using サイクル (saikuru):\n「彼は小さなgreenhouse(温室)を、再利用する材料で建てた。」\nBut the first version seems more natural.\n\nFinal translation: \n「彼は小さないronshīを、回収した材料で建てた。」\n</think>\n彼は小さないronshi(温室)を、回収したzairyō(材料)でtsuketai(建てた)。
推論力は悪くないと思うんですが、どちらかというと日本語の学習データが少ないのが原因かと思います。deepseek-r1 に対する日本語の追加学習モデルである hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest も動かしてみたかったんですが、マシンパワーが足りずローカル環境では動かせませんでした。
おわりに
当初は一切繋げることを想定していなかった LLM と dptran に思わぬところで接点ができて、試してみたら案外簡単にうまくいったといった結果でした。既存のモノ同士を API で繋げることで新しいことができる楽しさというのは絶大です。
なんとなくLLM を翻訳機に使うのは調教するのが難しそうで敬遠していましたが、割と適当なプロンプトでもそれなりに良い回答を返してくれることがわかったのは大きな収穫だと思っています。
特に、本家の DeepL API が対応していない言語にまで対応できるのは嬉しい点です。まだ各モデルがどの言語に対応しているのか把握できていませんが、無数の言語をローカルマシンで翻訳できるのはロマンを感じますね。
今後も独自 API 対応に向けて dptran を発展させていきたいと思っています。DeepL API 側が提供している機能全てに対応させ、さらに拡張性をもたせるよう進化させていきたい所存です。